
Scripting : useful text processing commands
 DigitalBox
DigitalBox- Scripting
- March 13, 2025
Today the scripting series is relative to text processing.
The commands below are useful when you need to handle text via the Terminal or when scripting.
| Command | Description |
| nano | Simple and user-friendly text editor |
| vim | Powerful and highly configurable text editor |
| lpe | Lightweight text editor |
| awk | Pattern scanning and processing language for text manipulation |
| gawk | GNU implementation of awk with additional features |
| sed | Stream editor for filtering and transforming text |
| cut | Extracts sections of lines from a file based on a delimiter |
| csplit | Splits a file into multiple parts based on patterns |
| split | Divides a file into smaller files of a specified size |
| diff / zdiff | Compares files line by line. |
| cmp | Compares two files byte by byte |
| comm | Compares two sorted files line by line and shows differences |
| sha256sum / md5sum / sha1sum | Computes checksums for file integrity verification |
| tr | Translates or deletes characters in a file |
| wc | Counts lines, words, and characters in a file |
| sort | Sorts lines of text files. |
| tee | Reads input and writes to both standard output and files |
Nano editor
Nano is a basic text editor and might be the default editor in some situations (like when using git commands).
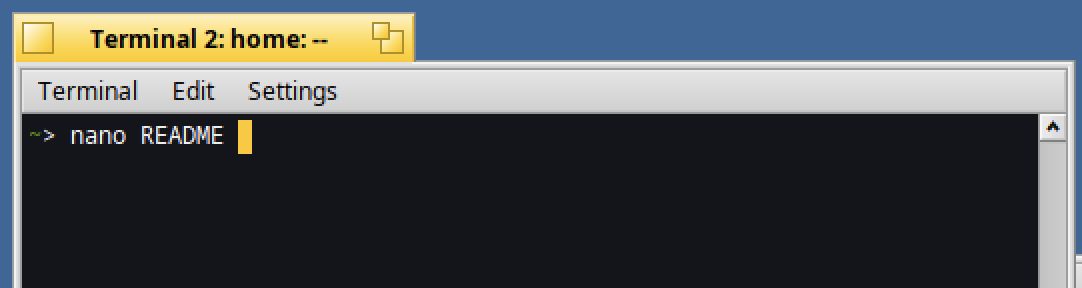
In order to use nano to create a new text file, type in a Terminal :
nano README
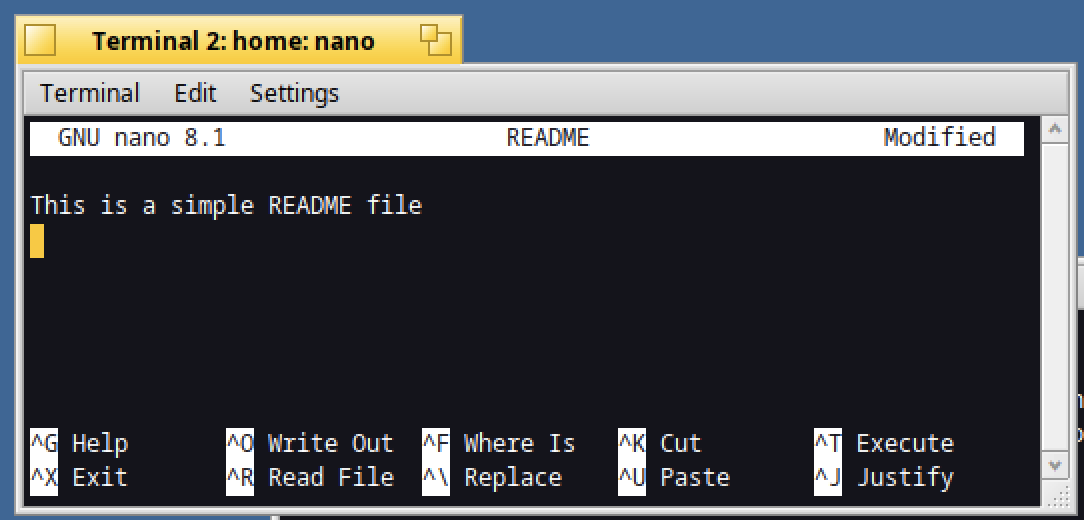
Then type a text of your choice :
When you need to save the file, use the Ctrl+O command :
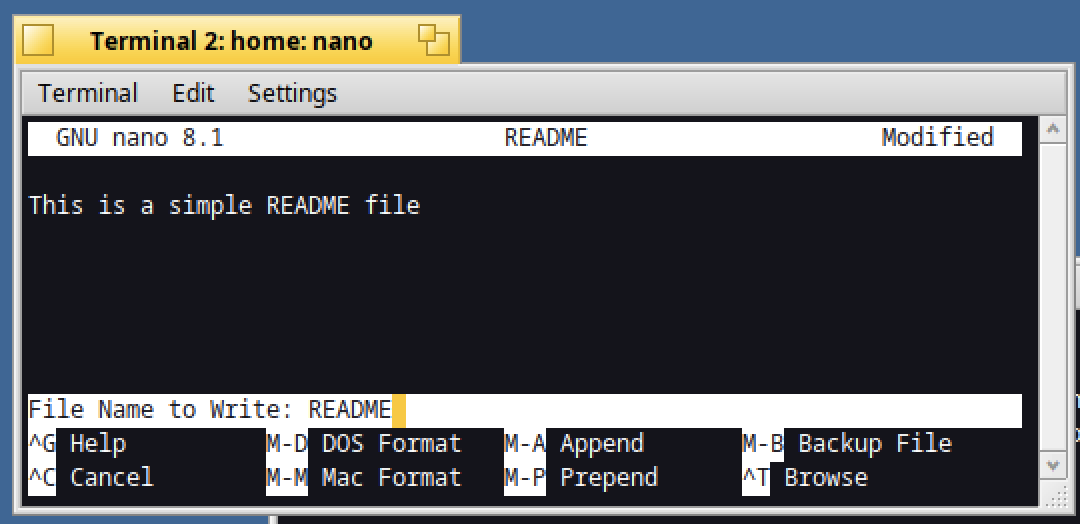
Validate with return.
In case you need to delete the current line, type Ctrl+K :
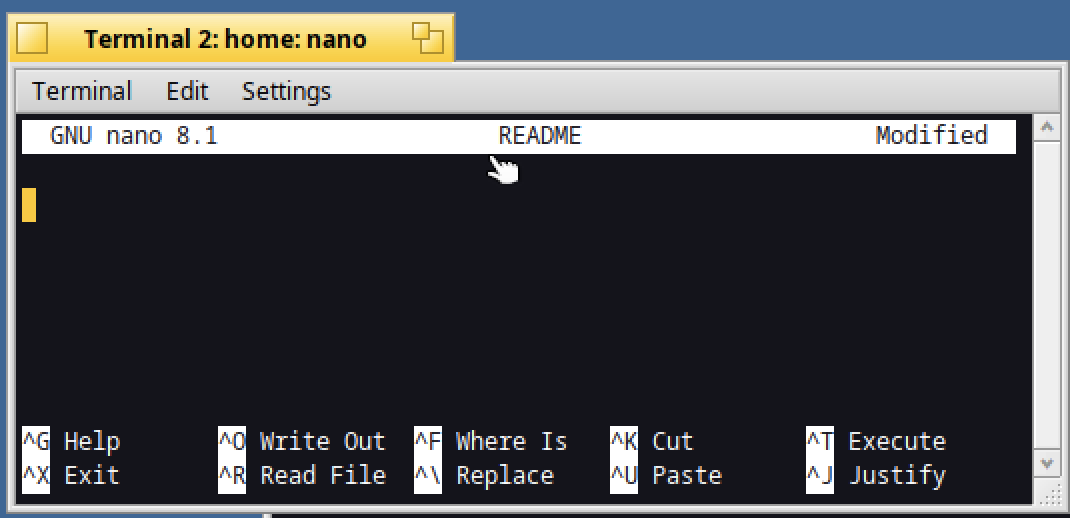
It will save the line content in the current buffer.
When you need to paste the current buffer, type Ctrl+U :

Above the file content contains two times the sentence because Ctrl+U was hit two times :)
When you need to search for a word, type Ctrl+F and enter the string to search (READ below) :
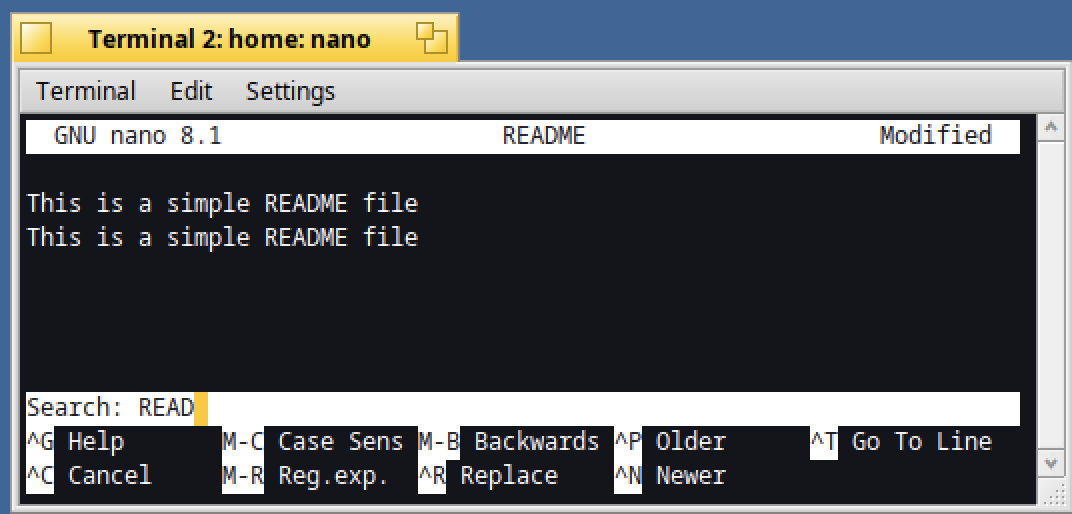
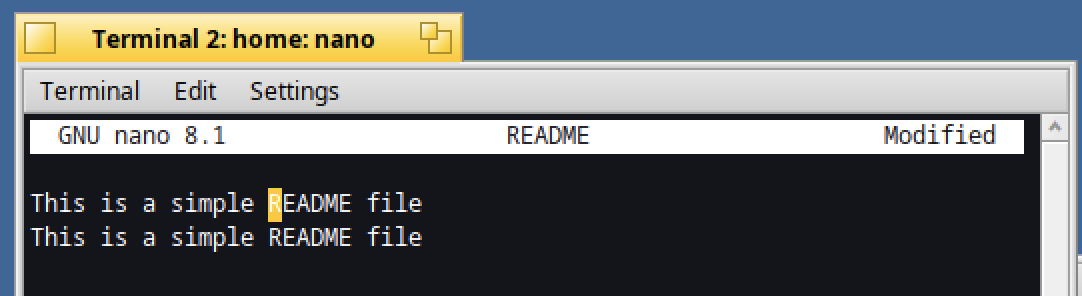
The first string found will then be displayed :
Finally, when you need to quit nano, type Ctrl+X.
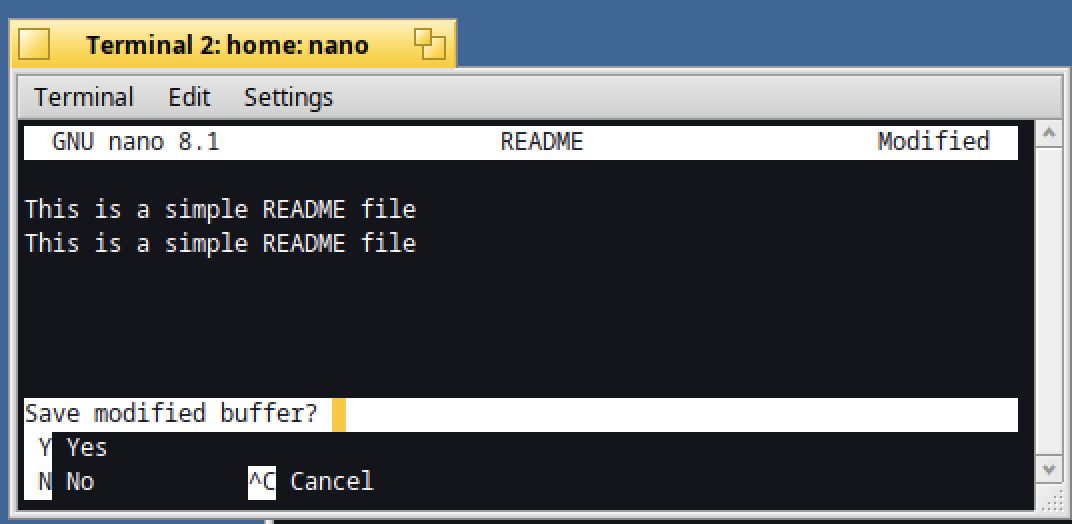
Confirm with Y or N if you want to save the changes made on the file.
VIM editor
VIM is a powerful text editor, so I will not go through all its details.
Instead I will only showcase the basic commands.
In order to create a new text file, type in a Terminal :
vim README
What is a bit disturbing the first time you use VIM - compared to nano - is that the text edition is not possible :
It's because VIM default mode is not edition, but only display of the content.
In order to put VIM in edition mode, hit the "I" key (like "insert") :

Then you can edit your README file like below :
Once you are happy with your changes, exit the edition mode by hitting "Esc" key.
Then enter ":w" in order to write the file :
Hit "Enter".
Once done, the file is written as indicated by the below message :

When you want to search for a string, hit the "/" key, then enter the string (like READ below) :
As you can see the string found is highlighted : )
Then you can quit VIM by hitting ":q" then "Enter" :
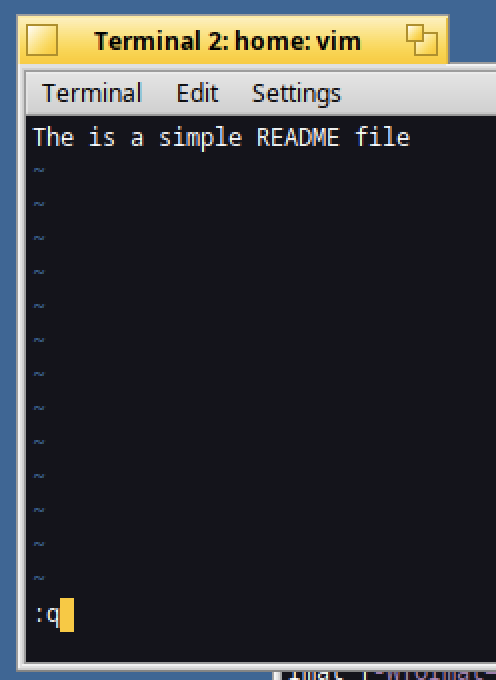
Great :)
Pe editor
Under Haiku, I advice you to use the default "Pe" editor.
In order to open or create the README file, type in a Terminal :
lpe README

"lpe" means lightweight Pe editor.
If you would like to discover the editor, you can read the article Mastering Pe editor.
Manipulate text with awk
Text edition is great, but what about manipulating text content ?
For that you can use the awk command.
Awk lets you transform any kind of text when separator character is identified.
By default the separator is space (" ") or tab.
For instance, below we will display only the 4th word and the 7th word of the netstat result where a line with "listen" pattern is identified:
netstat -n | awk '/listen/ { print $4, $7 }'
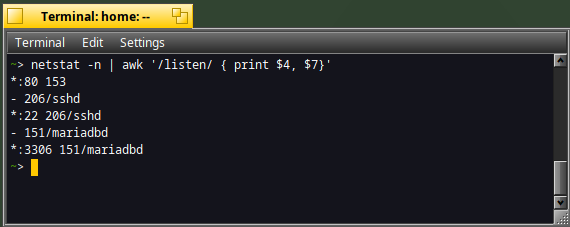
It indicates that three services are listening :
- port 80 : the Nginx web server (it's running on my machine)
- port 22 : the SSH daemon
- port 3306 : the MariaDB daemon
You can also ask awk for more complex text manipulation.
Do you need to know which lines are more than 800 characters in the Art fortune file?
It's easy, just type :
awk 'length($0) >800' /system/data/fortunes/Art
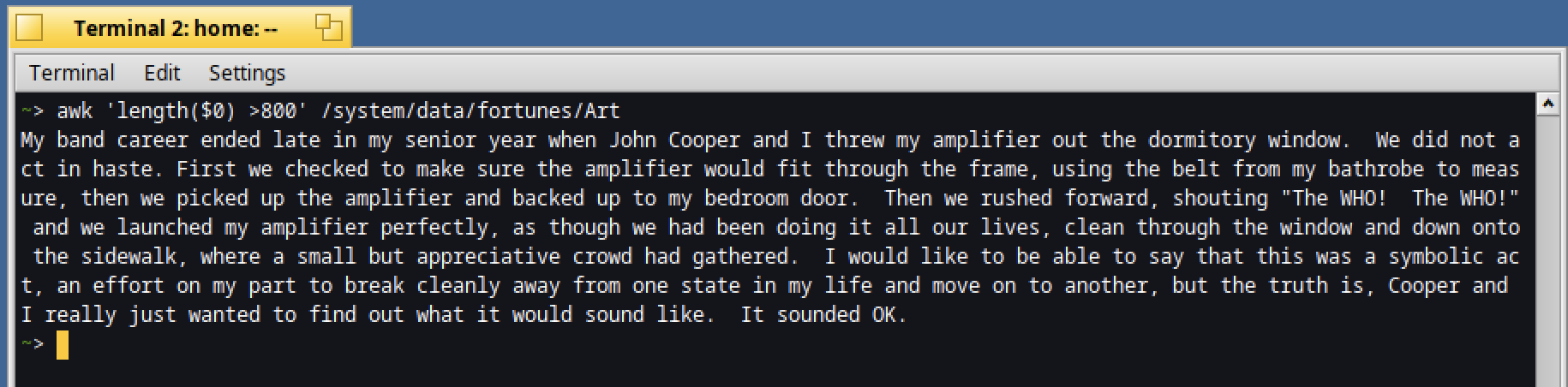
Or do you want to know how many times the word "John" is used ?
awk '/John/ { count++ } END { print count } ' /system/data/fortunes/Art
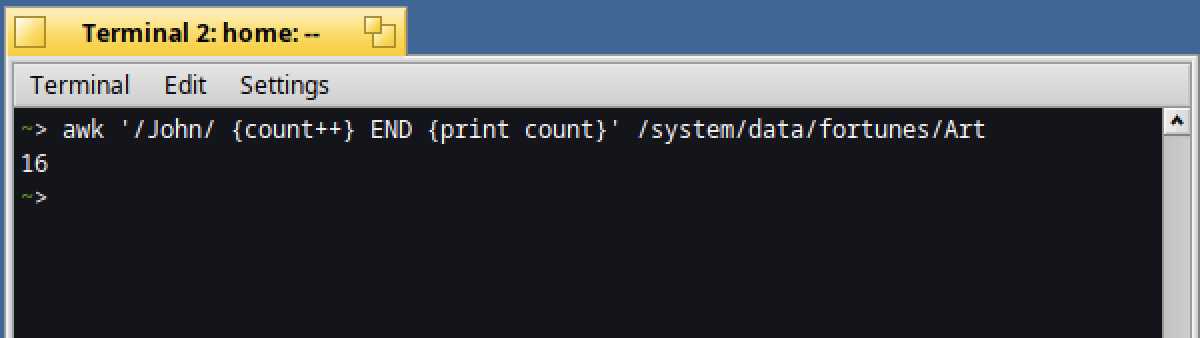
Nice, isn't it ?
Manipulate text with gawk
Awk is a great tool, however in case you need to perform more complex tasks, you might need to use gawk.
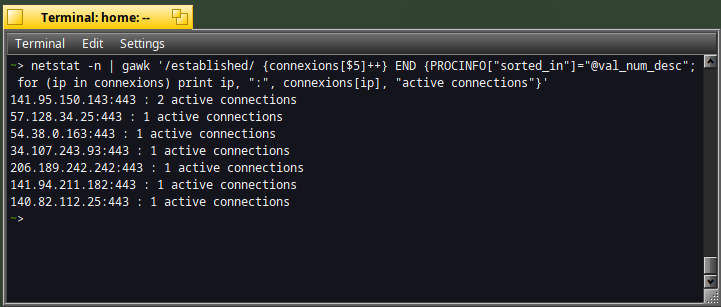
Below is a command to identify with gawk the number of active connections per ip address :
netstat -n | gawk '/established/ {connexions[$5]++} END {PROCINFO["sorted_in"]="@val_num_desc"; for (ip in connexions) print ip, ":", connexions[ip], "active connections"}'
Cleanup file with sed
The sed command - which means stream editor - allows to change the content of a file for various usages.
For instance, I'm regularly annoyed when I write a recipe with the Pe editor.
I often have a "trailing space" error.
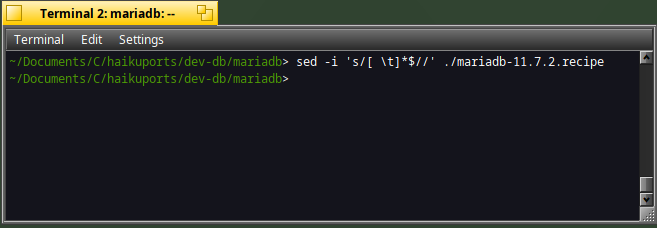
In order to avoid than, a good practice before commiting my changes to github is to clean the recipe file with sed as below :
sed -i 's/[ \t]*$//' ./mariadb-11.7.2.recipe
There can be many other usages for sed :)
Extract content with cut
Do you want to list the user accounts available on your system ?
For that you can use the cut command with the "passwd" file :
cut -d: -f1 /etc/passwd
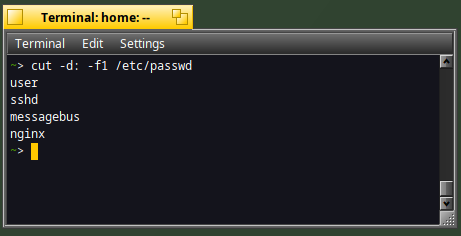
On my system "nginx" server is installed, that's why the "nginx" user appears in this file.
Manipulate files with csplit
If you need to manipulate config files, the csplit command can be interesting.
Many config files have some sections like in the fppkg.cfg file :
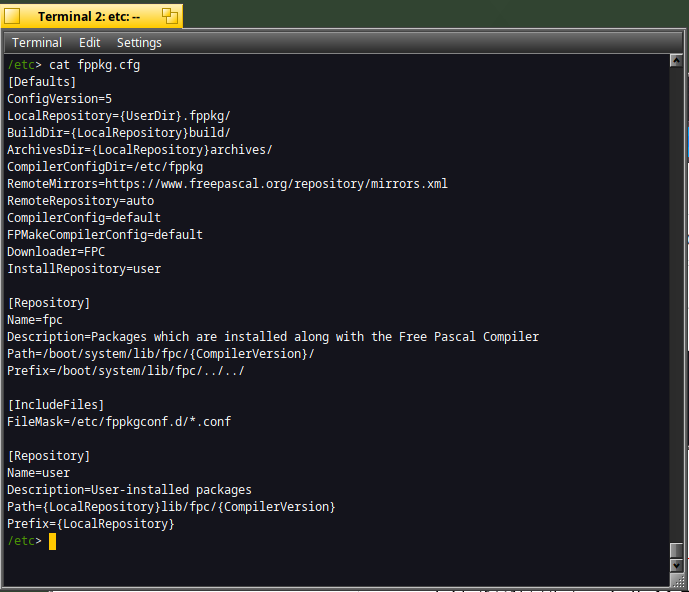
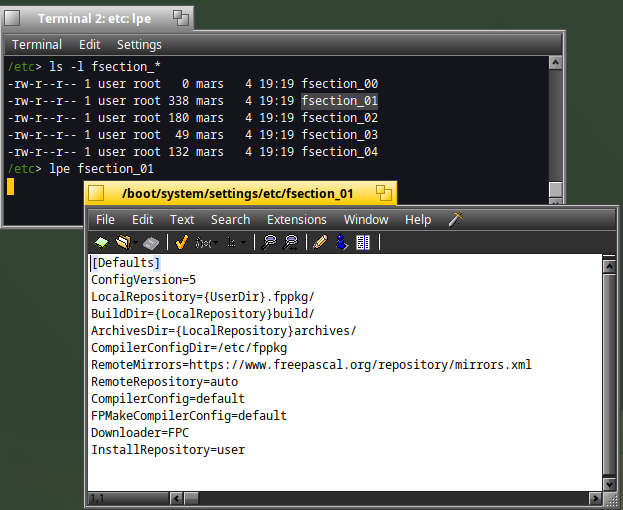
The sections available are [Defaults], [Repository], etc
What about generating for each section a dedicated file ?
For that type :
cd /etc
csplit -f fsection_ fppkg.cfg '/^\[.*\]$/' '{*}'
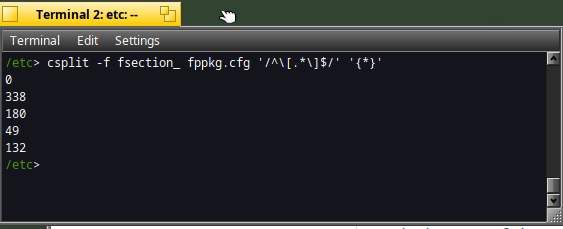
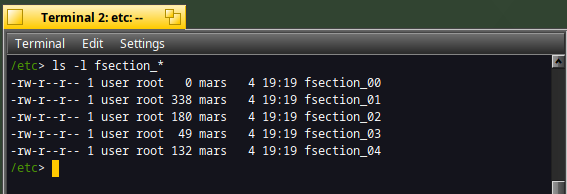
The csplit command works nicely and generates the files below :
If you look at the second file generated, it's a file dedicated to the [Defaults] section:
Great :)
Manipulate files with split
Imagine you have a large file, and you have a constraint about archiving this file on another media.
What about splitting this file into several parts, each part having a specific size.
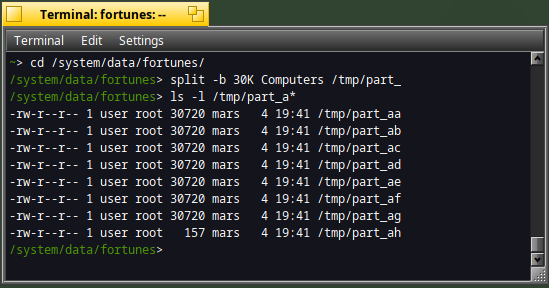
For instance, let's split the "Computers" fortune file into several files of 30 Kb :
split -b 30K Computers /tmp/part_
Check differences with diff
In case you need to compare the content of two files, diff is the command to use.
For instance, you can compare what has changed between two recipe files :
diff /boot/home/Desktop/mariadb-11.7.2.recipe /boot/home/Desktop/mariadb-11.7.2.recipe-changed
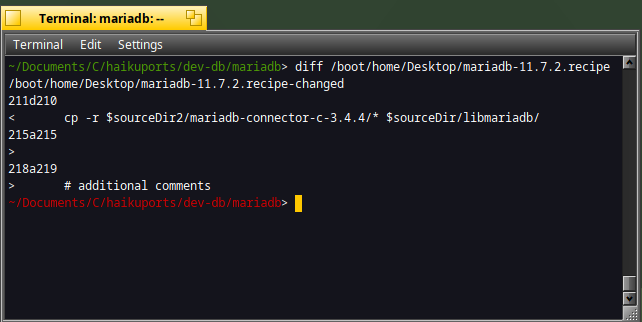
The output format is as below :
- < : show the lines of the first file
- > : show the lines of the second file
- d (delete) : line is deleted
- a (add) : line is added
- c (change) : line is changed
You can also make a diff between gzip archive files (".gz") :
Check binary files with cmp
When you need to compare binary files, you can use the "cmp" command :
cmp /system/apps/StyledEdit /system/apps/StyleEdit
cmp /system/apps/StyledEdit /system/apps/Icon-O-Matic
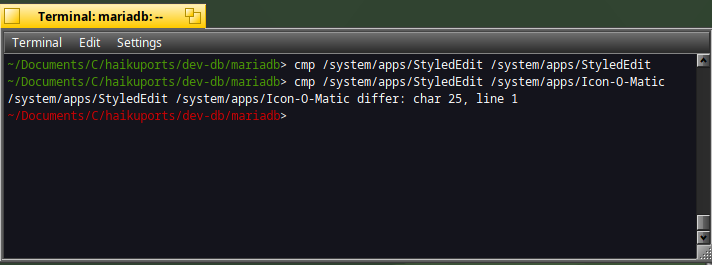
If the binaries are exactly the same, no result is returned.
If the binaries differ, the first position of the difference will be displayed.
Compare sorted files with comm
What about identifying applications which are available in the DeskBar versus the ones available in the apps folder ?
Let's do that with the "comm" command !
In a Terminal type :
ls -l /system/apps/ | awk '{ print $9 }' > system_apps.txt
ls -l /boot/system/data/deskbar/menu/Applications | awk ' { print $9 } ' > deskbar_apps.txt
comm <(sort system_apps.txt) <(sort deskbar_apps.txt)
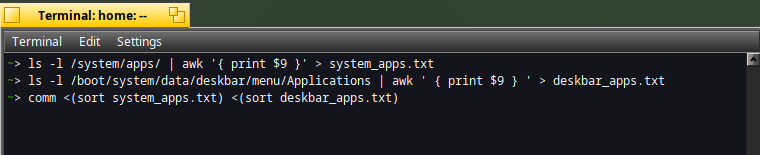
The output is as per below :
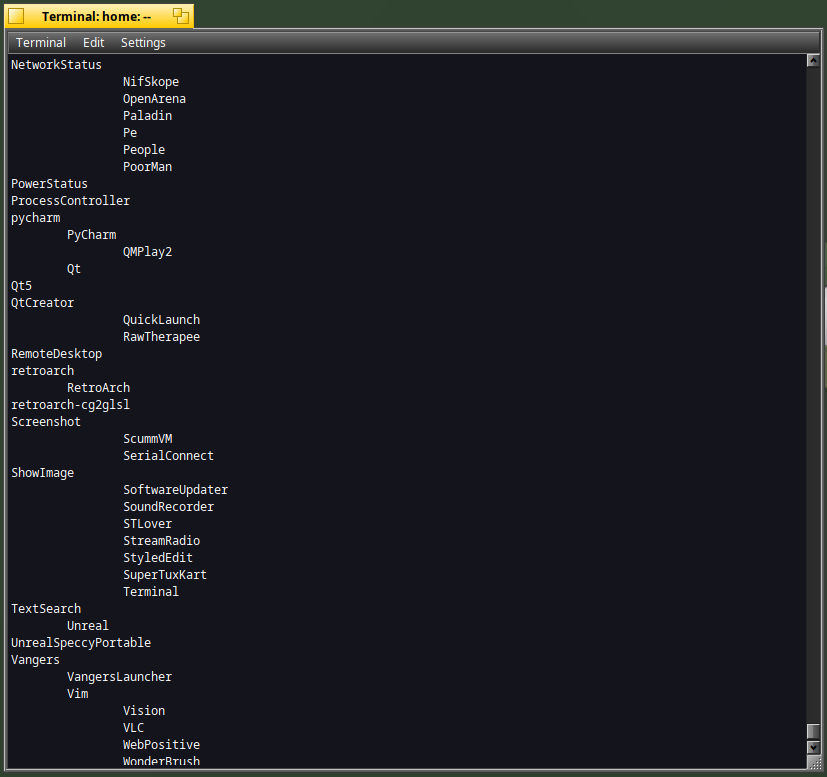
The first column indicates that the application's name is only available in "system" folder (first file). It's the case for instance for :
- ShowImage
- Screenshot
The second column indicates that the application's name is only available in the "deskbar" folder (second file). It's the case for :
- RetroArch
- Vim
The third column indicates that the application's name is available in both "system" and "deskbar" folders. It's the case for :
- Magnify
- SoftwareUpdater
- WebPositive
Please note that the above script could be enhanced in order to ignore lower/uppercase characters to have better results :)
Control files checksum
Checking the checksum of a file can be useful to verify its integrity after a download.
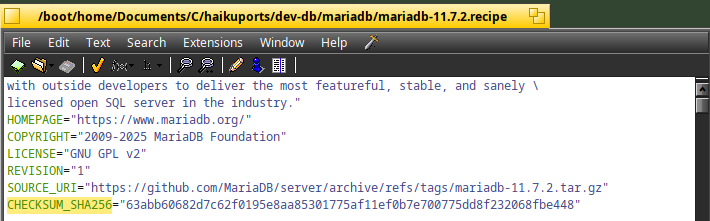
One possible command for that is "sha256sum".
This command is used in the recipe file from HaikuPorts when an archive file is downloaded :
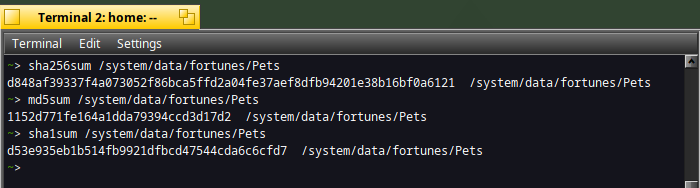
To compute the checksum of the Pets fortune file, type :
sha256sum /system/data/fortunes/Pets

The first value returned is the checksum :)
In case you need a good compromise between security and cpu usage, you can use "md5sum" or "sha1sum" commands :
md5sum /system/data/fortunes/Pets
sha1sum /system/data/fortunes/Pets
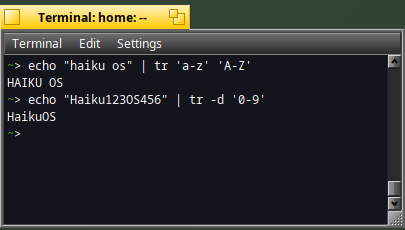
Translate string with tr
What about translating a content to another ?
Let's change lowercase characters to uppercase ones or remove numeric characters:
echo "haiku os" | tr 'a-z' 'A-Z'
echo "Haiku123OS456" | tr -d '0-9'
Count lines and characters with wc
A command which I often use is the "wc" (word count) command.
Do you need to count the number of files in the current directory ?
ls -l | wc -l
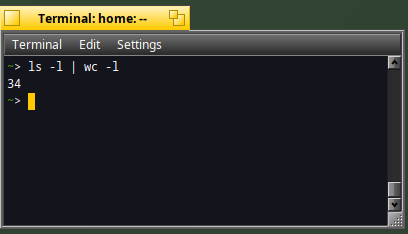
In the example below, 34 files (or folders) are located in the home directory :)
Sort file content with sort
What about sorting the content of a file or the result of a script ?
For that, you just need to use the "sort" command.
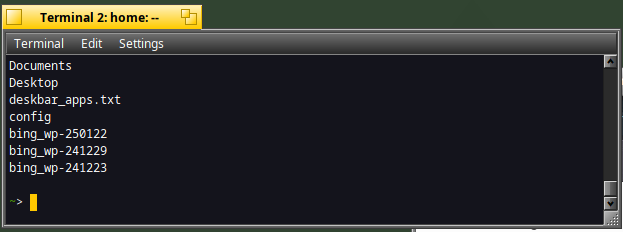
ls -l | awk ' { print $9 } ' | sort -r
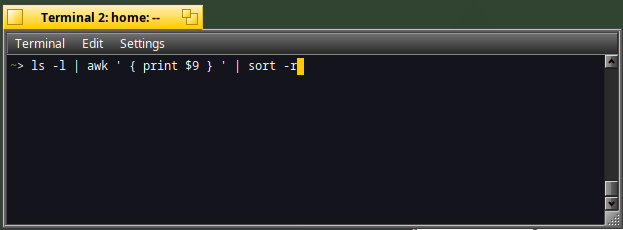
As you can see, the last files displayed are the ones which starts with the first alphabetical order:)
Write to multiple output with tee
Do you need to redirect the result of a command both to the output display and in a file ?
For that, you can use the "tee" command.
ls -l | tee files.txt
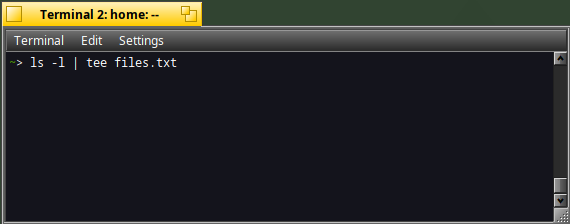
The result of the "ls" command is displayed in the Terminal :
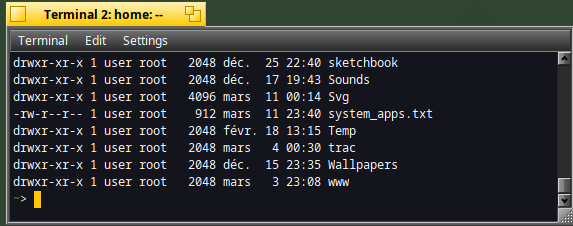
But it has also been redirected to the "files.txt" file :
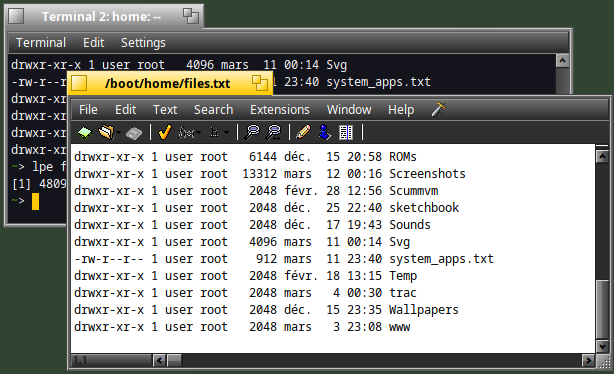
I hope you have found this article in the scripting series useful.
Other categories of commands for scripting will be proposed in the coming weeks :)